![]() 论文标题:Refining and Synthesis: A Simple yet Effective Data Augmentation Framework for Cross-Domain Aspect-based Sentiment Analysis
论文标题:Refining and Synthesis: A Simple yet Effective Data Augmentation Framework for Cross-Domain Aspect-based Sentiment Analysis
作者:王海宁,何慷,李波波,陈蕾,李霏,滕冲,韩旭,姬东鸿
论文链接:https://openreview.net/forum?id=FAA7ZQrB5h
单位:武汉大学
会议名称:The 62nd Annual Meeting of the Association for Computational Linguistics
一、引言
基于方面的情感分析(ABSA)是一项基本的情感分析任务,旨在分析方面层面的情感。
它通常涉及提取多个情感元素,包括方面、观点和情感极性。近十年来,ABSA 引起了越来越多的关注,随着深度学习的发展,很多模型和方法都能在方面级情感分析数据集上取得不错的效果。然而大多数用于模型训练的方法只使用相同领域的数据,需要细粒度的标记数据。这对于标注数据较少的新兴领域来说是个问题,会阻碍性能的提高。
对此,一些研究侧重于开发具有领域迁移能力的模型以应对这些挑战,将学习到的知识从有标签的源领域转移到无标签的目标领域。然而这些研究大多基于判别模型,需要针对特定任务进行定制化设计。此外,还有一些研究借助特定领域的词典,使用基于规则或神经网络的方法来获取外部语义词典。虽然这些方法在特定数据集上的表现值得称赞,但它们对外部知识的过度依赖损害了其泛化能力。最近,通过将每个任务形式化为序列到序列问题,将各种任务整合到一个统一框架中的方法取得了可观的成果。然而,这类的研究忽略了两个关键点: 首先,目标域未标注数据是由源域训练的模型用伪标签标注的,几乎没有质量控制,导致不准确和错误传播。其次,生成的标签数据的标签和文本模式是单调的,因此限制了训练好的 ABSA 模型的鲁棒性和泛化能力。
在本文中,我们旨在设计一个简单而有效的框架来解决 ABSA 数据扩增中的上述不足,该框架被称为 "Refining and Synthesis Data Augmentation (RSDA)"。我们的框架大致包括两个步骤: 首先,利用自然语言推理(NLI)过滤器精炼生成的标记数据以控制数据质量。其次,通过新颖的标签组合和解析方法合成多样化的标签数据,为了解决生成数据多样性有限的问题,我们的多样性增强方法主要从信息密度和表达多样性两个角度来提高多样性。最后,我们的框架已在 32 个跨领域实验中进行了测试,与 7 个强大的基线相比证明了它的有效性。
二、 方法
1、方法概述
我们的 RSDA 框架主要包括两个步骤,如图1所示:
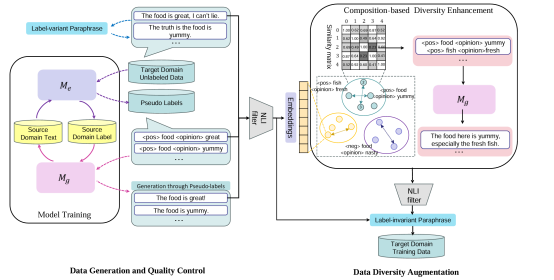
图1:RSDA框架图
Step1:数据生成和质量控制。
首先,我们从源领域训练好的提取和生成模型中获取目标领域的伪标签和相应的生成样本。
然后,我们使用自然语言推理(NLI)模型作为过滤器去除不正确的样本。
Step2:数据多样性增强
在这一步中,我们采用了基于组成的多样性增强(composition-based diversity enhancement)和基于转义的多样性增强(paraphrase-based diversity enhancement)来生成新的标签或改变其上下文。
2、数据生成和质量控制
2.1数据生成
采用之前工作(Deng 等人,2023 年)的方法,我们同时训练标签提取模型和文本生成模型。然后我们利用提取模型从目标域句子![]() 中提取伪标签
中提取伪标签![]() 。基于伪标签
。基于伪标签![]() ,样本生成模型可以生成一个新的样本
,样本生成模型可以生成一个新的样本![]() . 数据生成后,我们会得到一个新的目标域标注数据
. 数据生成后,我们会得到一个新的目标域标注数据![]() 。
。
2.2.数据质量控制
由于生成模型是根据源领域训练的,因此它倾向于生成与源领域更一致的文本,从而导致数据不那么流畅。此外,提取的伪标签所带来的噪声也会传播到生成的文本样本中。为了解决这些问题,我们采用了自然语言推理(NLI)过滤器来控制生成数据的质量。具体来说,我们将原始目标域文本![]() 作为前提,将新生成的文本
作为前提,将新生成的文本![]() 作为假设。
作为假设。
NLI 过滤器可以确定一对前提和假设之间的关系,表述为:
![]()
其中![]() 可以是蕴含、中立以及矛盾,当
可以是蕴含、中立以及矛盾,当![]() 和
和![]() 之间出现矛盾关系时,表明生成的文本
之间出现矛盾关系时,表明生成的文本![]() 难以从原文中推断出来,应予以过滤,如下图2(a)所示;在质量控制之后,一些生成的问题样本将会被去除,从而保留得到高质量的标记数据
难以从原文中推断出来,应予以过滤,如下图2(a)所示;在质量控制之后,一些生成的问题样本将会被去除,从而保留得到高质量的标记数据![]() 。
。

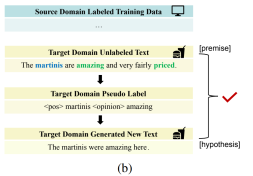
图2:NLI过滤器示意图
3、数据多样性增强
在上一步中,我们通过 NLI 过滤器过滤了模型生成的目标域标签样本。然而,根据人工审察,我们发现了两个需要改进的不足:(1)由于训练资源的限制,生成模型往往会生成简单或重复的句子。(2) 虽然使用 NLI 过滤器可以提高生成数据的质量,但它会过滤掉部分样本,从而牺牲文本表达和模式多样性。为了解决这些问题,我们着重从两个维度对数据进行多样化处理,即信息密度和表达多样性。
3.1以组合为基础的多样性强化
首先,我们使用已标注目标域数据的标签进行词法聚类。具体来说,我们使用 Sentence Transformers 中的 MiniLM-L6将标签![]() 编码为其向量表示得到
编码为其向量表示得到![]() 。随后,应用 K-means 聚类算法将标签划分为
。随后,应用 K-means 聚类算法将标签划分为![]() 簇,
簇,![]() 的计算方式如下所示:
的计算方式如下所示:
![]()

然后,同一聚类中每对数据点的文本之间的语义相似度用余弦相似度来衡量,计算公式为:
![]()
其中,![]() 和
和![]() 表示由 MiniLM-L6对文本
表示由 MiniLM-L6对文本![]() 和
和![]() 编码后的向量表示。具体来说,我们选择语义相似度低的数据点以增加数据的多样性。接下来,我们将
编码后的向量表示。具体来说,我们选择语义相似度低的数据点以增加数据的多样性。接下来,我们将![]() 和
和![]() 并入生成模型,得到合成文本
并入生成模型,得到合成文本![]() ,一个新的、更平滑的文本。例如,在聚类和相似性计算之后,我们选择两个标签<pos> food <opinion> yummy和<pos> fish <opinion> fresh进行合并,然后输入到生成模型中得到“The food in here is yummy, especially the fresh fish”。事实上,由于我们选择的是同一聚类中最远的两个标签,合并后的两个标签并不能保证相同的情感极性,这就为合并后的样本提供了更多的可能性。通过合并不同的标签,可以提高信息密度和标签多样性。
,一个新的、更平滑的文本。例如,在聚类和相似性计算之后,我们选择两个标签<pos> food <opinion> yummy和<pos> fish <opinion> fresh进行合并,然后输入到生成模型中得到“The food in here is yummy, especially the fresh fish”。事实上,由于我们选择的是同一聚类中最远的两个标签,合并后的两个标签并不能保证相同的情感极性,这就为合并后的样本提供了更多的可能性。通过合并不同的标签,可以提高信息密度和标签多样性。
3.2 以转义为基础的多样性强化
对于基于转义的多样性增强,我们设计了两种方法来增强目标领域的标注数据,核心思想是利用转义来重写标签或其上下文,从而生成新的数据。
表1:基于转义的多样性增强实例

(1)标签变体转义(Label-variant Paraphrase)
由于标签的非语言性,我们采用了一种间接的方法来实现标签变体转义。如表1所示,我们将一个转义模型应用于原始目标域无标签文本![]() ,这样就能生成一段新的转述文本,称为
,这样就能生成一段新的转述文本,称为![]() 。然后就可以使用提取模型
。然后就可以使用提取模型![]() 提取伪标签
提取伪标签![]() 。
。
需要注意的是,在这一阶段,由于转义工具是直接应用于原始文本的,所有单词都可能被改写,因此提取的伪标签也可能与原始标签不同。之后,生成模型 ![]() 将根据伪标签
将根据伪标签 ![]() 生成一个新句子
生成一个新句子![]() 。这种方法不仅与标签不变的转述过程一致,而且还增强了
。这种方法不仅与标签不变的转述过程一致,而且还增强了![]() 的多样性和表达能力。
的多样性和表达能力。
(2)标签不变转义(Label-invariant Paraphrase)
我们还对前面步骤中生成的目标域标签样本进行了转义以丰富其文本模式,避免简单的句子结构。这进一步解决了模型产生过于简单句子结构的倾向。如表1所示,我们利用提示鼓励转义工具在将文本![]() 改写为
改写为![]() 时加入标签
时加入标签![]() 。然后,我们使用后处理方法确保转述文本
。然后,我们使用后处理方法确保转述文本![]() 包含标签
包含标签![]() 。在这一阶段,我们尽量保持目标域标签样本中的标签不变,同时转换其上下文,从而合成出更多样化的数据。
。在这一阶段,我们尽量保持目标域标签样本中的标签不变,同时转换其上下文,从而合成出更多样化的数据。
三、实验:
1、数据集设置:
为了验证我们的框架在跨领域设置中的有效性,我们在四个领域的基准数据集上进行了广泛的实验:Restaurant、Laptop、Device 和 Service。这些数据集被广泛用于ABSA,数据来源于2014、2015和2016年的SemEval挑战赛以及关于数字设备的评论和关于服务的评论。
考虑到数据集之间的领域相似性,我们选择了几个不同的源到目标领域对进行实验。具体来说,在 AE 和 AESC 任务中,根据先前的工作(yu-etal-2021-cross,gong-etal-2020-unified,yu-etal-2023-cross),我们排除了涉及Laptop域和Device域之间转移的实验,因为它们的相似性很高。由于数据源的限制,我们的实验只使用Restaurant和Laptop数据集来完成 AOPE 和 ASTE 任务。此外,由于 R14、R15 和 R16 共享相同的域,因此省略了它们之间的实验。因此,AE、AESC 共有 10 个跨域实验,AOPE 和 ASTE 共有 6 个跨域实验。我们的最终训练数据集包括原始域标签数据集和 RSDA 框架处理过的目标域数据集。
2、任务设置:
我们选择 Micro-F1 作为实验的主要评估指标,只有当预测标签完全匹配真实标签时,才认为该标签是正确的。此外,为了评估增强样本的多样性,我们采用了多样性评价指标,
具体来说,![]() 表示所有方面词中独特方面词的百分比,而
表示所有方面词中独特方面词的百分比,而![]() 表示所有观点词中只出现一次观点词的百分比。此外,我们还计算了所有生成样本中多面向词的百分比。对于 AE 和 AESC 任务,生成样本的多样性完全由
表示所有观点词中只出现一次观点词的百分比。此外,我们还计算了所有生成样本中多面向词的百分比。对于 AE 和 AESC 任务,生成样本的多样性完全由![]() 决定,而对于 AOPE 和 ASTE 任务,多样性是
决定,而对于 AOPE 和 ASTE 任务,多样性是 ![]() 和
和 ![]() 的平均值。
的平均值。
3、结果对比
表2:跨域 AE 和 AESC 任务的结果
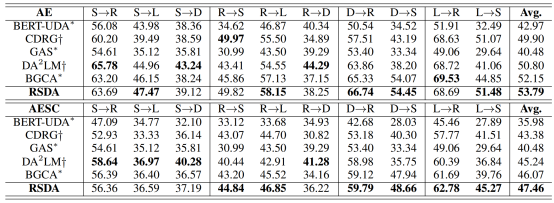
表2列出了跨领域设置中AE和AESC任务的总体结果。可以看出,在十种不同的跨领域设置中,我们提出的框架在大多数领域对中的表现都优于最先进的方法。对于 AOPE 和 ASTE 任务,我们在表3所示的六个不同领域对上进行了实验,RSDA框架在 AOPE 任务中的平均 F1分数提高1.45%,在ASTE 任务中的平均 F1分数提高了 2.04% 。此外,通过实验,我们注意到以下几点:
(1) 在所有四项任务中,我们提出的框架平均性能优于现有方法。我们将这一改进归功于在整个过程中采用了高质量过滤和多样化增强策略,从而确保了生成样本的质量。此外,我们的框架与 BGCA 完全兼容,并对其进行了进一步优化。
(2) 我们观察到,基于编码器-解码器结构(如 T5)的方法比基于 BERT 的方法表现更好。
我们推测,采用编码器-解码器结构的生成模型通过更好地捕捉上下文信息,在处理抽象任务方面表现出色。它们通过自我关注机制和递归机制全面理解整个文本。
(3) 我们的框架在某些域对中的表现不如DA2LM,尤其是在 S 作为源域的跨域实验中。我们发现在源域数据量明显低于目标域数据量的实验中面临着挑战,猜测可能的原因是模型在提取和生成方面都没有得到足够的训练,从而限制了提取和生成能力。
表3:跨域 AOPE 和 ASTE 任务的结果

4、消融实验
表4:四个任务上的消融实验
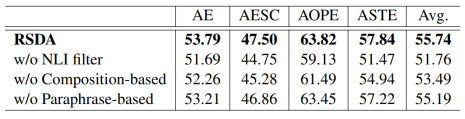
为了分析框架的有效性,我们以 micro-F1 和多样性为指标进行了消融实验,具体结果如表4所示。首先,当我们移除 NLI 过滤器时,我们观察到所有四个任务的 F1 分数都显著下降了约 3.98%。这表明了基于 NLI 的质量控制的有效性,因为 NLI 过滤器可以消除存在语义和格式错误的示例。去除基于组成的多样性增强后,F1 分数平均下降了约 2.25%,在 ASTE 和 AOPE 任务中观察到的影响尤为显著。我们推测,基于组合的多样性增强对标签蕴含信息更丰富的任务有更明显的影响。

图3:关于基于组合的多样性增强的消融实验
为了评估基于成分的多样性增强的贡献,我们对其进行了消融实验,结果如图3所示。我们使用多方面样例的比例作为衡量指标。去除基于成分的多样性增强后,所有四项任务的这一指标都有不同程度的下降,其中 ASTE 和 AOPE 任务的下降幅度接近 50%,这表明基于成分的多样性增强确实增强了样本的信息密度。
5、生成数据的质量评估
表5:生成数据的质量评估
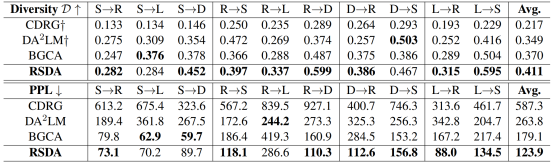
为了证明我们的框架在跨领域环境中的有效性,我们对十个领域对的 AESC 任务中生成的样本进行了质量评估。我们采用困惑度(PPL)来衡量生成样本的流畅度,并按照先前学者的方法采用 GPT-2进行困惑度计算。考虑到 BGCA 方法没有生成额外的数据,导致生成的样本数量有限,为了公平起见,我们的实验随机选取了每种方法生成的 500 个样本进行困惑度测试。表中的结果表明,我们的框架生成的样本的困惑度明显低于其他方法。我们推测,NLI 过滤器有效地缓解了由域偏移现象导致的生成非流利样本的问题。
我们还使用![]() 来评估生成样本的分布情况。如表的前四行所示,与其他方法相比,我们的模型表现出更高的多样性。值得注意的是,在 D->S 任务中,虽然 DA2LM 方法的多样性值高于我们的方法,但我们的框架获得的 F1 分数却高出 12.91% 。这表明,我们的方法不仅提高了生成样本的多样性,而且覆盖了目标领域中更多的方面词。
来评估生成样本的分布情况。如表的前四行所示,与其他方法相比,我们的模型表现出更高的多样性。值得注意的是,在 D->S 任务中,虽然 DA2LM 方法的多样性值高于我们的方法,但我们的框架获得的 F1 分数却高出 12.91% 。这表明,我们的方法不仅提高了生成样本的多样性,而且覆盖了目标领域中更多的方面词。
四、结论:
在本文中,我们为跨领域 ABSA 任务提出了一个两步数据增强框架。第一步使用 NLI 过滤器控制样本质量并过滤低质量伪标签;第二步使用标签合成和解析方法增强数据的多样性。最后我们在跨领域设置中进行了32个实验,证明了我们的框架的有效性,它优于7种强基线。我们的方法不仅减少了错误伪标签造成的错误传播,还增强了目标领域中生成的标签数据的多样性和流畅性。该方法简单而有效,无需太多努力即可实现并扩展到其他领域和任务。未来我们将探索我们的框架在其他结构信息提取任务中的推广能力。
上一篇:暂无数据
