
论文信息
题目:Cross-Domain Sentiment Analysis via Disentangled Representation and Prototypical Learning
期刊:IEEE Transactions on Affective Computing
作者:Qianlong Wang, Zhiyuan Wen, Keyang Ding, Bin Liang, and Ruifeng Xu*
单位:哈尔滨工业大学(深圳)
论文链接:10.1109/TAFFC.2024.3431946
1 摘要:
情感分析(Sentiment Analysis)是自然语言处理领域的一项基本任务。它旨在自动预测评论文本(如电影评论和产品评论)的情感极性(例如,积极或消极)。最近,许多基于监督学习的方法,如神经网络和预训练语言模型(Pretrained Language Models, PLMs),都显著提高了情感分析的性能。
尽管这些监督方法取得了理想的结果,但它们的性能在很大程度上依赖于大量标注的训练数据,而这些数据往往因人工代价过高而不可获取。此外,在实际场景中,为每个新领域标注大量的训练数据是不可能的。因此,跨域情感分析(Cross-Domain Sentiment Analysis, CDSA)越来越受到人们的关注,它利用源域中的知识(有标注的数据)来帮助目标域中的情感预测(仅对无标注的数据进行预测)。然而,由于领域差异的存在,直接使用源领域上训练的情感分类器,在目标领域推理时会导致性能下降。
为了解决这个问题,早期方法主要使用源域和目标域的统计信息来捕捉共享的情感指示特征(即不同域之间具有高度共现的单词)。随着深度学习的快速发展,一些研究探索了神经网络模型来缓解CDSA中的领域差异问题。为了连接源领域和目标领域,这些神经模型主要通过各种技术提取域不变特征,如协同训练、基于注意力的迁移和对抗训练。其中,对抗训练是一种广泛使用且有效的方法,它的目的是通过域鉴别器来区分域不变量和域特定特征。这些研究旨在为每个评论文本生成一个领域不变的情感特征向量。然而,由于领域和情感特征之间的共享特征空间,可能会导致混合表示。此外,在获取领域不变的情感表示时,模型可能会过度泛化某些特征,导致有价值的领域特定情感信息的丢失以及领域和情感特征之间的混淆。
解纠缠表示学习(Disentangled Representation Learning)认为,一个智能系统将受益于将世界的潜在意义分离(解纠缠)为其表示的不相交部分。对于CDSA,我们希望将不同的因素编码到单独的离散空间中,每个离散空间具有不同的语义。这种解纠缠的表示方法不仅符合CDSA的要求,而且避免了先前主流研究的对抗性训练缺陷。
本文从一个新的角度研究了CDSA任务,并尝试使用解纠缠表示学习的方法来解决它。具体来说,首先将编码器输出的文本表示分解为两个不同且独立的特征,即情感特定特征和领域特定特征。为了实现这一目标,使用两个线性层将一个文本表示映射到两个不同的特征空间,因为不同的线性变换可以自动提取潜在语义,而不会过滤目标信息。然后,分别将情感特定特征和领域特定特征输入到情感分类器和领域分类器中。在这里,使用源标注数据为情感分类器提供监督信号,同时利用源和目标数据为领域分类器提供监督信号。理想情况下,每个样本的情感特定和领域特定特征应该很好地分离。为此,在训练过程中引入一个简单的解纠缠损失,以分离情感和领域信息,该损失旨在使情感特定特征摆脱领域信息,并捕获文本中的情感内容。
然而,学习到的情感特定特征最终被应用于目标领域的情感分析。如果只使用源标注数据的监督信号,不发挥目标未标注数据的潜在价值,那么情感特定特征可能会存在改进的空间。理想情况下,我们认为,目标域中具有可能不同(或相同)情感的高质量情感特定特征应该彼此远离(或靠近)。原型学习(Prototypical Learning)可以使实例更接近它们所属的原型,并将实例与其他无关的原型分开。受此启发,通过原型学习使目标领域的情感特征在情感类上更具区分性。具体而言,将情感分类器的权重视为原型嵌入。对于目标域数据,具有相同类的情感特定特征应围绕与该类对应的原型嵌入。这里,利用从情感特定特征和原型嵌入之间的相似性中导出的软伪标签来最小化熵损失,以实现目标数据的更紧密聚类。
我们在四个领域的评论数据集上进行了广泛的实验。结果表明,与现有方法相比,本文所提出的方法可以实现最先进的性能,表明了其有效性和优越性。
2 方法

方法架构图
上图显示了所提出方法的overview。方法由三个模块组成:文本编码器模块、解纠缠表示学习模块和原型学习模块。文本编码器模块首先利用PLM来获得源域和目标域数据的文本表示。然后,解纠缠表示学习模块对文本表示执行解耦操作,以导出情感特定特征和领域特定特征。随后,原型学习模块通过原型学习进一步提高情感特定特征的质量。
文本编码器模块
在这项工作中,采用BERT作为文本编码器,将输入文本编码为广义的上下文表示。BERT可以处理不同含义的相同token,并学习丰富的上下文语义信息,从而很好地连接源域和目标域:
![]()
这里,e是输入文本的嵌入序列、h是输入文本相应的上下文表示序列。在这项工作中,我们将与[CLS]对应的上下文表示视为输入文本的表示z。
解纠缠表示学习模块
在获得文本表示后,使用解纠缠表示学习模块对其进行解纠缠操作。该模块旨在将文本表示z解耦为相应的情感特定特征和领域特定特征。为了实现这一点,使用两个线性层将一个文本表示映射到两个不同的特征。
![]()
![]()
其中W是参数矩阵,b是偏差。根据等式,文本表示z将分别通过权重![]() 和
和![]() 投影到情感特定特征
投影到情感特定特征![]() 和领域特定特征
和领域特定特征![]() 。在这里,两种不同的线性变换能够有效地提取有用信息并分离无关噪声。我们希望这两个特征具有代表性:情感特定特征对情感标签能够准确地预测,并且领域特定特征包含来自样本的足够的领域信息。然而,如果没有监督信号,两个分离的特征表示可能会相交,甚至毫无意义。为此,引入了两个分类器(即情感分类器和领域分类器)来学习良好的解纠缠特征。
。在这里,两种不同的线性变换能够有效地提取有用信息并分离无关噪声。我们希望这两个特征具有代表性:情感特定特征对情感标签能够准确地预测,并且领域特定特征包含来自样本的足够的领域信息。然而,如果没有监督信号,两个分离的特征表示可能会相交,甚至毫无意义。为此,引入了两个分类器(即情感分类器和领域分类器)来学习良好的解纠缠特征。
具体来说,给定输入文本的情感特定特征![]() ,将其输入softmax分类器,以获得其在情感标签上的预测概率分布:
,将其输入softmax分类器,以获得其在情感标签上的预测概率分布:
![]()
其中![]() 和
和![]() 分别是情感分类器的权重矩阵和偏差。然后,可以在源标注数据上计算监督交叉熵损失。
分别是情感分类器的权重矩阵和偏差。然后,可以在源标注数据上计算监督交叉熵损失。
对于从线性变换后产生的领域特定特征![]() ,我们希望它包含丰富的领域信息。为此,从源数据和目标数据中为其提供相应的监督信号。在此基础上,引入了一个领域分类器,旨在预测文本的领域标签,即来自源域或目标领域。特别是,首先将
,我们希望它包含丰富的领域信息。为此,从源数据和目标数据中为其提供相应的监督信号。在此基础上,引入了一个领域分类器,旨在预测文本的领域标签,即来自源域或目标领域。特别是,首先将![]() 输入到域分类器中以计算领域概率分布。然后,源域和目标域样本的交叉熵损失可以定义为:
输入到域分类器中以计算领域概率分布。然后,源域和目标域样本的交叉熵损失可以定义为:

![]() 其中
其中![]() 和
和![]() 分别是权重和偏差。
分别是权重和偏差。![]() 是所有未标注数据中第i个文本的one-hot领域标签。这个优化目标将鼓励线性变换来提取领域特征。
是所有未标注数据中第i个文本的one-hot领域标签。这个优化目标将鼓励线性变换来提取领域特征。
随后,添加了一个解纠缠的损失,以便使用情感特定特征更好地执行CDSA。通过这种损失,期望情感特定特征不会包含任何领域信息,从而成为领域分类边界上的模糊点。具体来说,将情感特定特征输入到领域分类器中,并使用无域标签来优化第一个线性层的参数:

![]()
其中KL是Kullback-Leibler散度损失函数的缩写,0.5是希望特征成为域分类边界上模糊点的无域标签。
原型学习模块
在解纠缠表示学习模块中,情感特定特征的学习过程仅利用源标注数据。因此,如果不利用未标注的目标数据,则在目标测试数据上推理时性能可能较差。为了缓解这个问题,通过原型学习使用目标未标注数据进一步提高学习到的情感特定特征的质量。具体来说,首先通过嵌入特征空间的单个原型来表示每个情感类。这里,为了简单起见,将情感分类器的权重视为原型嵌入,即v1和v2(从方程4中的W导出)分别用于表示正向情感原型和负向情感原型。然后,使用情感特征和原型嵌入之间的语义相似性作为伪标签,将每个目标样本分配到两个原型中。因此,损失可以表述如下:
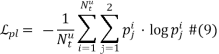

其中![]() 代表第i个样本与第j个原型的相似性;sim是一个余弦相似性函数,用于评估情感特定特征与原型之间的语义相似性。
代表第i个样本与第j个原型的相似性;sim是一个余弦相似性函数,用于评估情感特定特征与原型之间的语义相似性。
最后,采用两阶段训练策略来优化所提出方法的参数。第一阶段,旨在学习一个有能力的领域分类器,以提供有利的解纠缠信号。第二阶段,通过联合训练模式优化相关参数,学习高质量的情感特定特征。
3 实验结果
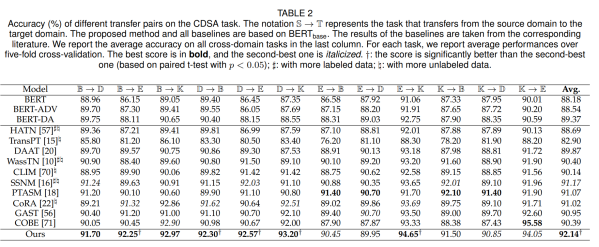
主实验
为了全面评估所提出方法的性能,我们将其与一些先进的基线进行了比较。在这里,所有基线都使用BERT作为PLM以进行公平比较。表2报告了提出的方法和基线的主要结果。可以从这个表中得出以下结论。
(1)所提出的方法可以在12个跨域任务上实现了SoTA性能,平均准确率为92.14%。同时,我们的方法在7个任务中产生了最佳结果。这表明,提出的使用解纠缠表示和原型学习的方法在目标域上比基线更有效、更通用。
(2)大多数使用目标未标注数据和迁移策略的模型都超过了BERT。这表明,目标未标注数据和迁移策略都可以提高CDSA任务的性能。此外,与BERT相比,BERT-ADV和BERT-DA的改进很小,这表明纯粹使用对抗学习并不能很好地解决CDSA问题。一种可能的解释是,来自域鉴别器的监督信号可能会干扰学习情感特定特征。
(3)对于CDSA,进一步利用目标未标注数据可以增强文本表示,从而提高目标领域的分类性能。例如,CLIM通过对源域和目标域数据的对比学习来学习区分文本表示,并取得了令人满意的结果。这从侧面说明了使用目标未标注数据的潜在益处。此外,不同的迁移策略表现出不同的性能。例如,基于关键枢轴的转移策略(即SSNM)比基于距离的策略(即WassTN)产生更好的平均分。

消融实验
消融结果如表3所示。根据实验结果,可以得出以下结论。首先,去除两个关键成分之一(即解纠缠的表征学习![]() 和原型学习
和原型学习![]() )会导致整体性能下降,证明了它们在CDSA任务中的有效性。此外,两者的下降幅度不同,这表明去除前者比去除后者损失更多的性能。其次,在去除域分类器后(
)会导致整体性能下降,证明了它们在CDSA任务中的有效性。此外,两者的下降幅度不同,这表明去除前者比去除后者损失更多的性能。其次,在去除域分类器后(![]() ),所提出方法的性能在所有变体中下降幅度最大。因此,得出结论训练良好的领域分类器对于解纠缠的表示学习至关重要。最后,单阶段训练(
),所提出方法的性能在所有变体中下降幅度最大。因此,得出结论训练良好的领域分类器对于解纠缠的表示学习至关重要。最后,单阶段训练(![]() )的性能明显不如两阶段训练。一个可能的原因是,同时优化所有损失可能会带来一些干扰,无法学习到训练良好的领域分类器。
)的性能明显不如两阶段训练。一个可能的原因是,同时优化所有损失可能会带来一些干扰,无法学习到训练良好的领域分类器。

结合不同预训练模型的结果
为了展示结合不同PLM时所提出方法的性能,选择BERT、XLNet、RoBERTa和SentiX作为代表性PLM,使用它们提供文本上下文表示并进行比较实验。表5显示了实验结果。根据此表,可以得出以下结论:(1)在不同的PLM下,我们的方法可以带来一致性的改进,表明它可以与不同的PLM集成,并产生令人满意的跨域结果。(3)在PLM中,SentiX取得了最好的结果。我们猜测,这是因为在预训练期间添加几个情感感知目标可以帮助学习领域不变的情感知识。
4 结论
本文将解纠缠表示学习和原型学习用于CDSA。具体来说,首先通过解纠缠表示学习从文本中学习情感特定特征和领域特定特征。此外,使用无域标签设计了一个简单的解纠缠损失,以最小化情感特定特征中的域信息。然后,通过原型学习进一步提高了所学习的情感特定特征的质量。它的目的是将具有潜在同类的目标未标注数据的情感特征表示相互接近。在四个数据集上进行的广泛实验表明了所提方法的有效性。

