

题目:EmoGen: Emotional Image Content Generation with Text-to-Image Diffusion Models
会议:CVPR 2024
作者:杨景媛、冯嘉伟、黄惠*
单位:深圳大学
项目主页:https://vcc.tech/research/2024/EmoGen
本工作首次将生成任务引入视觉情感计算领域,提出情感图像内容生成(Emotional Image Content Generation,EICG) 任务,旨在生成语义明确、多元,并能传达指定情感的图像。本工作通过建立映射网络,将情感空间与CLIP空间对齐,通过属性损失和情感置信度的设计,为抽象视觉情感提供了具体语义解释。此外,本工作针对新任务提出了三个新的评价指标;定量结果、可视化实验和用户调查验证了本工作的有效性;在情感概念分解、情感迁移和情感融合上的应用,展示出本工作在情感理解和艺术设计上的巨大潜力。
近年来,扩散模型在图像生成领域上取得了卓越的进展,尤其是在文本生成图像(text-to-image)方向上,用户可以通过手工设计提示词或指定个性化物体,生成超逼真、高质量的图像。现有的文生图扩散模型通常在具体概念(如猫咪,房屋,山脉)的生成上表现出色,但是在表达抽象概念(如开心,愤怒,悲伤)时却遭遇瓶颈。在日常生活中,摄影师和艺术家在创作时,往往希望有情感化的呈现和设计。
我们很自然地想到:计算机能否生成震撼人眼,且触动人心的图像呢?生成情感是一项充满挑战的任务。情感是认知级的概念,而图像是像素级的实体,其中存在难以逾越的情感鸿沟。为了将情感和图像建立联系,现有工作试图通过改变图像的颜色、风格来实现情感迁移,但是效果往往差强人意。有心理学研究表明,视觉情感通常是由图像中的某些具体语义唤起的。
文生图扩散模型大多是借助CLIP空间的共用语义表征来实现的,但是本文发现CLIP空间不能很好地捕捉情感和图像间的关系,由此引入了情感空间,实现同类情感相聚,不同情感远离,并提出映射网络对齐情感空间和CLIP空间,为后续情感的语义化解释提供了保障。
由于情感图像内容生成是一项新任务,本文提出了三个新的评价指标,分别从语义明确性、情感一致性、语义多样性等多角度来评估生成结果。定量结果、可视化实验和用户调查从多个维度验证了本工作的有效性。
本工作主要贡献如下:
首次提出情感图像内容生成任务,并针对新任务设计三个评价指标;
引入情感空间,建立与CLIP空间的映射;提出属性损失和情感置信度,确保生成图像的语义多样性和情感一致性;
定量和定性结果证明了本方法的有效性,展现了在情感理解和艺术创作应用上的潜力。
本方法分为情感表征和情感内容生成两部分,通过两阶段网络训练实现。情感表征旨在将情感标签转换成张量形式的特征表达,以便后续与语义特征建立映射。情感内容生成旨在生成语义明确且与情感鲜明的内容。

图1 网络训练过程,情感表征(一阶段)学习情感空间,情感内容生成(二阶段)将情感空间映射到CLIP空间,旨在生成图像内容具有情感一致性,语义明确性和语义多样性。
情感表征
CLIP空间尽管有强大的语义表征能力,但是并不能很好地刻画情感关系。由此,基于EmoSet数据集中的情感图像和标签,本文结合交叉熵损失训练情感编码器。图像经过情感编码器提取特征后形成了情感空间。好的情感空间应该有以下特点:同类情感特征聚集,不同类情感特征远离。
情感内容生成
为了使生成的情感图片具有明确语义,本文将情感空间映射到CLIP空间。文中使用非线性映射层结合 CLIP 内置的 transformer,将抽象情感和具体语义关联起来,使得扩散模型能够理解情感知识。同时,为了保留 CLIP 原有知识,本文冻结 transformer 和线性映射层的参数,只训练非线性映射层。
所使用的损失函数包含了常用的隐扩散模型损失![]() 、针对语义设计的属性损失
、针对语义设计的属性损失![]() 和针对情感设计的情感置信度
和针对情感设计的情感置信度![]() 。
。
![]()
其中ε是给原图像添加的噪声,![]() 是预测噪声的网络,
是预测噪声的网络,![]() 是添加了t时刻噪声的隐特征。
是添加了t时刻噪声的隐特征。
映射后的向量尽管有鲜明的情感色彩,却可能在语义表达上不明确。属性损失的设计理念是利用标签加强对于生成内容的语义引导。具体来说,计算CLIP文本编码器输出的属性特征和映射后的视觉特征之间的余弦相似度,并利用交叉熵损失优化该过程。
情感置信度的设计理念是,EmoSet 中的属性并非都与情感相关。例如,一棵普通的树可能不会唤起强烈情感,但一只怒吼的狮子可能会使人感到恐惧或愤怒。通过实验观察,本文发现属性损失![]() 可以保证生成明确的语义内容,而隐扩散模型损失
可以保证生成明确的语义内容,而隐扩散模型损失![]() 用于维持全局的情感色彩。为平衡整体色彩和局部语义之间的关系,本文使用情感置信度
用于维持全局的情感色彩。为平衡整体色彩和局部语义之间的关系,本文使用情感置信度![]() 来刻画各属性与各情感的关联程度。本文所使用的损失函数如下:
来刻画各属性与各情感的关联程度。本文所使用的损失函数如下:
![]()
作为第一个视觉情感内容生成的工作,本文选取最相近的个性化文生图扩散模型作为对比方法。图2中展示了3个情感类别上的生成结果,相较对比方法,本文生成了高保真、高质量的图像,且语义明确、多元,能唤起较为强烈的目标情感。

图2 论文方法与现有文生图方法和消融实验的定性比较。
如下表所示,与相关方法对比,本方法在保真度、全局多样性、情感一致性、语义明确度和语义多样性五种指标上取得了最优越的性能。
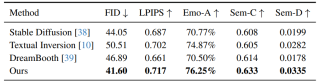
表1 在五个指标上与现有最好的方法比较
本方法在多个子任务上具有广阔应用前景,其中包括:情感分解、情感迁移和情感融合。
情感分解
基于视觉情感源自内容的假设,本文试图可视化同一情感下的多元语义表达。举例来说,图3中的冲浪板、自行车和运动场,都是可以引发激动情感的物体。这些情感概念表现出了多元和明确的语义,具有唤起强烈情感的能力。通过分解视觉情感,我们不仅能够生成丰富语义的情感图像,还能进一步理解情感唤起的过程。这个结果揭示了情感和语义的紧密联系,这也和前文提到的心理学研究结论遥相呼应。

图3 情感分解,每个情感都能分解成多个语义,且每个语义都有对应的生成图像。
情感迁移
为进一步探索情感创造的可能性,本文将所学情感表征加入到中性物体的语义上,生成了具有情感色彩的、有创造力的图像,展现了本方法在艺术创作上的巨大潜力。
如图4所示,生成图像在保持原有语义的基础上,与表达情感的元素无缝衔接。以开心为例,在不同的语义条件下,本方法可以加入合理且多元的情感内容,如游乐园、野餐、公主、气球和彩灯。

图4 情感迁移,将中性物体和情感表征(开心,恐惧)结合生成图像。
情感融合
图5展示了情感融合时的有趣结果,当融合两个不同情感时,本方法既能保留各情感特有的内容,又能很好地融合两种不同的情感特征。当看到既有趣又可怕的脸时,我们能同时体验到开心和恐惧的情感。这一结果也为情感化的艺术设计提供了新的思路。

图5 情感融合,将两个情感结合生成图像。
正如理查德·费曼所说:“我无法创造,就代表我没有理解”,现有视觉情感计算大多集中在识别和分类问题上,这极大地限制了该领域的发展和深入。情感图像内容生成任务的提出,一方面连接了文本和视觉模态,使自动化的情感创作成为可能;另一方面也加深了对于视觉情感的理解,拓宽了该领域的研究范畴。研究团队希望该工作的提出,可以开拓新的研究领域,启发好的研究思路,鼓励研究者们在图像情感生成、跨模态情感理解等方向不断探索。

