题目:Revisiting Structured Sentiment Analysis as Latent Dependency Graph Parsing
期刊:2024 ACL
作者:周成杰,李波波,费豪,李霏,滕冲,姬东鸿
单位:武汉大学
论文链接:http://arxiv.org/abs/2407.04801
情感极性分析(Sentiment Analysis)一直是自然语言处理研究的热门话题。在该领域中,以往的研究主要集中在句子级别的情感极性分析任务上。近年来,细粒度(Fine-grained)的情感极性分析任务受到广泛的关注,从直觉上出发,句子层面的分析假定句子中只表达了一种情感,而在许多情况下,情况并非如此。因此,更彻底的分析需要在实体/方面层面进行,以抽取实体和相关方面,并对与这些实体和方面相关的情感进行分类。
根据抽取实体-情感元组的不同可以将细粒度(Fine-grained)的情感极性分析任务划分成多个代表性子任务:
基于方面的情感分析(aspect-based sentiment analysis, ABSA),旨在抽取Aspect(方面/实体)、情绪表达(Expression)、极性(Polarity)三种要素,表征了文本中对Aspect(方面/实体)的情绪表达(Expression)和对应的情感极性(Polarity);
观点挖掘(Opinion Mining, OM),旨在同时抽取Holder(主体)、Target(客体)、Opinion(观点)三种要素,表征了Holder(主体)对Target(客体)的Expression(观点)。
结构化情感分析(Structured Sentiment Analysis, SSA),旨在同时抽取Holder(主体)、Target(客体)、情绪表达(Expression)、极性(Polarity)四种要素,表征了Holder(主体)对Target(客体)的Expression(情绪表达)和对应的极性(Polarity)。
可以看到结构化情感分析的提出旨在覆盖先前两个任务及其子任务中对文本情感表达的缺失,同时覆盖到了情感表达、主体、客体和情感极性四个方面。在结构化情感分析中,情感四元组可以用Sentiment Graphs来具象化储存和表示(如下图1a所示)。
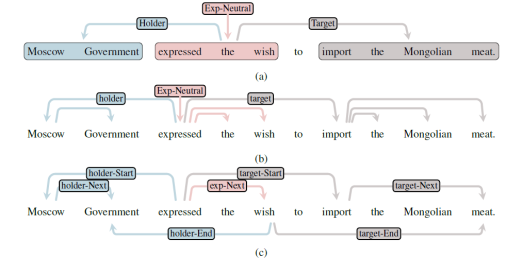
图1 (a)结构化情感分析任务示意,情感四元组(holder,target,expression,polarity)的图表示;(b)Barnes等人提出的SSA as Parsing范式(head-first);(c)Shi等人与Zhai等人提出的Table Filling范式
与ABSA和OM任务不同,SSA强调情感分析的结构化方法。先前对于多情感元素分析的主流方法是采用流水线的方式,分别进行主体Holder、客体Target和情感表达Expression的信息抽取等子任务,再进行情感分类。然而,这样的方法不能捕获多个子任务之间的依赖关系,且存在任务的误差传播。结构化方法意味着从情感依存图的角度出发,同时考虑多个子任务的抽取。Barnes等人于2021年提出了利用基于图的依存分析(Dependency Parsing)来捕获观点四元组内各要素之间的依赖关系,其中情感主体、客体和情绪表达都是节点,它们之间的关系则是弧。该模型当时在 SSA 任务上获得了最佳效果。然而,由于缺乏层次化的结构标注,各情感元素span内部结构很少被前人工作利用,这种缺漏也影响了span间的关系预测。例如,Barnes等人假定span的第一个词或者最后一个token作为根节点,Shi等人和Zhai等人同样关注span的边界token对整个span的注意力表示。得益于结构上的相似性,最近信息抽取任务中,涌现出了一大批工作,将原任务(Nested NER、Semantic Parsing etc.)归纳为Dependency/Constituency Parsing,并取得了不错的性能,但据我们所知,目前还缺少分析结构化情感的研究。
在本文中,受结构分析工作的启发,我们提出了SSA任务一个新的依存分析范式——基于潜在依存图(Latent Dependency Graph)的高阶依存分析方法,目标是在端到端的前提下,将扁平span结构建模为隐式依存图。通过这种方式,我们可以极大缓解Barnes等人提出的依存分析方法的扁平依存树先验约束,同时可以利用已有的一些成熟的依存句法分析技术,例如TreeCRF、高阶建模等等,来进行全局概率推断和引入结构化约束,提高SSA的性能。
我们与多个基线系统进行了性能上的评估比较,包括:
简单依存分析方法(Barnes等人),如图1b,该范式直接假定主体、客体、表达span中的第一个词或者最后一个词为依存树根节点,span中其他token直接与根节点相连,方法使用一阶双仿射注意力(Biaffine attention)依存分析器;
填表方法(Table Filling),如图1c,该范式不使用依存分析器,而是在序列长度*序列长度的二维表中预测主体、客体、表达span中的头-尾词关系与不同span间的头-头、尾-尾关系,在这种范式下,Shi等人使用GNN,而Zhai等人使用基于坐标轴(axis)的attention进行token-token关系预测。
我们在MPQA、DS-unis、MultiBooked-Catalan、MultiBooked-Basque等多个数据集上进行了此评估。实验结果和进一步的讨论证明了潜在依存图与相关结构分析在结构化情感分析任务中的潜力。
结构化情感分析任务(Structured Sentiment Analysis, SSA)的目的是抽取出文本中人们对创意、产品或政策等的看法,并结构化地表达为情感四元组 (h, t, e, p),包括Holder(主体)、Target(客体)、情绪表达(Expression)、极性(Polarity)四种要素,表征了Holder(主体)对Target(客体)的Expression(情绪表达)和对应的极性(Polarity)。例如图1a,输入句子“Moscow Government expressed the wish to import the Mongolian meat.”,输出情感四元组(“Moscow Government”,“import the Mongolian meat”,“expressed the wish”,“Neutral”)。

图2 长span示例
先前工作中忽视的span内部结构直觉上有助于确定span边界与预测属于同一四元组中不同span间的关系,特别是长span,很难直接通过边界词的注意力表示进行高效的概率推断。如图2所示,我们着重标出了expression——conceded与整个target span。可以明显看出,target跨度相当长,这使得边界(“US”和“year”)难以有效地表示整个跨度。相反,内部词“accession”为确定其为“conceded”一词的target提供了重要线索,而在目标范围内的其他单词充当其修饰符,帮助检测范围的边界。这种例子在数据集上占比非常多(统计情况如表1所示),所以这成为了SSA任务的性能瓶颈之一。

表1 各数据集中长span的统计(长度按照token数计算)
我们在基本的图依存分析方法上构建了结构化情感分析的潜在依存图分析系统,该系统(1)首先通过规则将扁平的情感依存图结构构建为潜在依存图结构;(2)基于给定的潜在依存图学习依存分析器,然后将依存分析器预测出的依存图恢复为标准情感依存图结构。
形式化来说,结构化情感分析需要实现两个目标:(1)确定各情感元素span的边界(2)预测span间的关系。这两个目标都可以借由对情感依存图的结构解析达成。
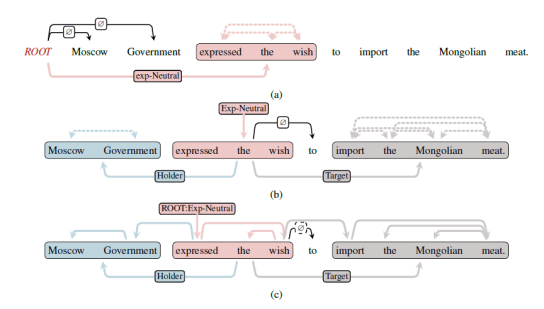
图3 (a)依存图构建一阶段:对每个expression span构建从伪根节点到该span的弧和span内潜在依存弧;(b)依存图构建二阶段:对每个expression span对应的holder span和target span构建弧,对span内构建潜在依存弧;(c)依存图的恢复:对依存分析器预测的概率最大依存图恢复成标准依存图结构,并经由子树确定span边界和span间关系,形成情感四元组抽取结果
![]() :图3a与图3b展示了我们构建潜在依存图的过程,对于情感表达expression,首先我们构建伪根节点到Expression的弧,弧标签设为exp和对应的情感极性,并在第二阶段接着构建Expression到主/客体的子树。对于span内部的弧我们不做任何假设(比如Barnes等人的扁平树强约束),将这个部分视为潜在的依存图,允许任何弧,并且不分配标签. 对于不属于Expression对应的span,将标签设为O。
:图3a与图3b展示了我们构建潜在依存图的过程,对于情感表达expression,首先我们构建伪根节点到Expression的弧,弧标签设为exp和对应的情感极性,并在第二阶段接着构建Expression到主/客体的子树。对于span内部的弧我们不做任何假设(比如Barnes等人的扁平树强约束),将这个部分视为潜在的依存图,允许任何弧,并且不分配标签. 对于不属于Expression对应的span,将标签设为O。
![]() :利用依存分析器预测依存图后,恢复为情感依存图结构。与句法分析相同,由于弧标签的概率分布和依存图结构独立,首先对伪根节点到句中每个token的弧进行分类,对于标签为Expression的弧,我们认为确定了情感表达span的中心词,并解码出剩下的树结构,通过遍历该树,找到了情感表达span的边界。从情感表达span到其他词,我们认为他们是该情感表达span对应的主、客体span的中心词,并以他们为起始,解码树结构并找到对应的span,最终我们收集所有形成的情感表达及其对应的主客体,得到最终的情感四元组预测。
:利用依存分析器预测依存图后,恢复为情感依存图结构。与句法分析相同,由于弧标签的概率分布和依存图结构独立,首先对伪根节点到句中每个token的弧进行分类,对于标签为Expression的弧,我们认为确定了情感表达span的中心词,并解码出剩下的树结构,通过遍历该树,找到了情感表达span的边界。从情感表达span到其他词,我们认为他们是该情感表达span对应的主、客体span的中心词,并以他们为起始,解码树结构并找到对应的span,最终我们收集所有形成的情感表达及其对应的主客体,得到最终的情感四元组预测。
与Structured Sentiment Analysis as Dependency Parsing的工作一致,我们使用类似于经典Biaffine Parser的架构来学习潜在依存图,不同的是,在考虑到最终目标和评估指标针对的是情感四元组的抽取准确率(Span F1),我们进一步提出了加入树评分的二阶拓展和span拓展。在依存树打分器后面我们后接了一个带约束的TreeCRF来进行树结构约束和全局推断,最大化树概率。这两个拓展均迁移自依存分析领域的最新相关工作(Constrained TreeCRF、Headed-span与second-order parser)。
我们的树评分包含一阶弧评分、二阶弧评分和带中心词span评分,如以下公式所示:

一阶弧评分:在得到每个token的上下文表示(BiLSTM状态输出)之后,分别使用MLP得到该词作为依存弧的head/modifier的表示,计算序列中任意两token的双仿射注意力得分如下:

二阶弧评分:在得到每个token的上下文表示(BiLSTM状态输出)之后,分别使用MLP得到该词作为二阶依存弧的head/modifier/siblings的表示,计算序列中任意三token的三仿射注意力得分如下:
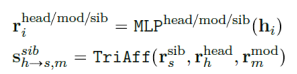
带中心词span评分:在得到每个token的上下文表示(BiLSTM状态输出)之后,分别使用MLP得到该词作为带中心词的span的head/left/right的表示,计算序列中任意两token的双仿射注意力得分如下:

训练时我们将最大化情感依存图 的概率近似为最大化构建的潜在依存图得到的依存树概率,并对此按情感表达Expression进行分解,最终训练的目标函数如下:

对于分解的Expression span树 ![]() 与对应的主/客体span树
与对应的主/客体span树 ![]() 对应的依存树概率为:
对应的依存树概率为:

此概率可以通过复杂度为O(n^3) 的TreeCRF来计算。与其他利用TreeCRF的信息抽取任务相同,一个主要的问题是经典的TreeCRF考虑的是所有候选树,然而在我们的依存图构建范式中引入了许多span的约束,所以依存树应当满足情感依存图的固有结构,这是经典TreeCRF不能做到的。所以参照结构化分析的已有工作,我们设计了一个满足二阶和带中心词span场景下的约束TreeCRF。

图4 带约束的TreeCRF的deduction rule表示
在表2中,我们报告了任务1上我们的提出的方法与多个基线系统的评估结果。
在Span F1指标方面,所提出方法在所有数据集上都表现出了卓越的性能,包括在MPQA数据集上holder提取的F1分数显著提高了7.2。此外,在评估情感依存图指标(SF1)时,该指标旨在同时评估span提取和span间关系预测准确度,所提出方法在NSF1和SF1分数上始终优于基线方法。值得注意的是,它比USSA基线平均高出2.12 NSF1和2.08 SF1。这种增强主要归功于我们采用的潜在依存图范式和高效的依存分析器,它高效地利用了span的内部结构信息并促进了span间关系的预测。

表2 SSA任务的实验结果
我们在表3中比较了同样依存分析器对于不同依存图建模范式的实验结果。为了评估将span建模为潜在树的重要性,我们研究了一阶方法的三种变体:1) First:利用第一个单词作为span的中心词。2) Last:使用最后一个单词作为span的中心词。3)Flat:类似于Barnes等人的Head-first法,将span单词直接附加在第一个单词上。结果显示,前两种方法的性能相当,但始终次优于我们的一阶方法。与所提出方法相比,flat方法被发现了性能的显著下降,表明潜在依存图对模型的分析性能做出了实质性贡献。
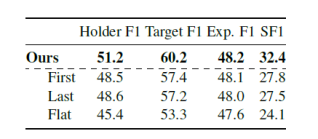
表3 不同依存图建模方式对SSA性能的影响
同时为了印证我们对于长span内部结构的观察和分析,我们对不同的情感表达span长度和情感四元组整体长度划分数据集并对基线模型进行了测试,考察模型在较长的span /tuples中的性能。Expression F1和SF1指标表明了所提出方法比基线的优越性,随着span/tuple长度的增加,性能差距越发显著。
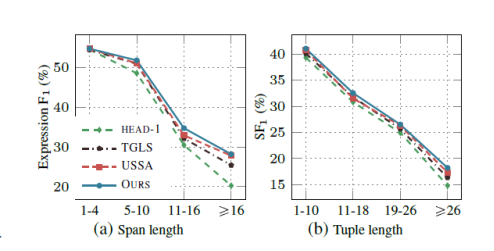
图5 不同长度的span和情感四元组的比较
在这项工作中,我们提出了一个结构化情感分析的新范式,通过潜在依存图分析实现结构化情感分析(SSA),将扁平情感span概念化为潜在子树。提出了一种基于TreeCRF的创新句法分析方法,旨在有效地集成span结构。实验结果表明,该方法在五个基准数据集上超过了之前的所有方法。综合分析验证了该方法增强SSA的有效性和一致性。
结构化解析方法在句法分析和信息抽取领域受到越来越多的关注,通过将潜在依存图解析方法引入情感极性分析任务,我们希望能够进一步探索和拓展结构化解析方法的应用领域,发挥其在复杂和精细环境下的计算语言学分析中的潜力。
