
题目: STICKERCONV: Generating Multimodal Empathetic Responses from Scratch
中文题目:STICKERCONV: 从零开始的多模态共情回复生成
作者:张逸群1#,孔繁恒1#,王培东1#,孙爽1,王凌帅1,冯时1*,王大玲1,张一飞1,宋凯嵩2
会议:ACL 2024, Long Paper, Main Conference
单位:1东北大学,2阿里巴巴集团
说明:#同等贡献,*通信作者
论文链接:https://arxiv.org/abs/2402.01679
项目主页:https://neu-datamining.github.io/StickerConv/
数据集:https://huggingface.co/datasets/NEUDM/StickerConv
摘要
表情包虽然被广泛认为可以增强在线互动中的共情交流,但在当前的共情对话研究中仍未得到充分探索,这主要是由于缺乏全面的相关数据集。在本文中,我们首先介绍了Agent for StickerConv(Agent4SC),它使用协作智能体交互来真实模拟人类使用表情包的行为,从而增强多模态共情交流。在此基础上,我们开发了多模态共情对话数据集STICKERCONV,其中包括12.9K 段对话、5.8K个不重复的表情包和2K个不同的对话场景,其中一段对话示例如图1所示。该数据集是多模态共情生成的基准。进一步,我们提出了PErceive and Generate Stickers(PEGS),一种多模态共情回复生成框架,并辅以一套基于大语言模型(LLM)的综合共情评价指标。实验证明,PEGS 能够有效生成与语境相关并能引起情感共鸣的多模态共情回复,从而有助于开发更细致入微、更引人入胜的共情对话系统。相关数据集和代码均已开源。
方法
1. Agent for STICKERCONV
面对缺乏多模态共情对话数据集这一关键挑战,我们计划使用LLM从零开始制作数据集。然而,LLM难以掌握人类的细微情感,而且难以发起超出明确指令的行动。这些缺点使得LLM和大型多模态模型LMM在生成多模态共情数据时表现不佳。为了解决这些问题,我们提出了Agent for STICKERCONV(Agent4SC),这是一个基于LLM的多智能体系统,旨在模仿人类的对话模式,并将表情包视作一种可被agent主动调用的工具。Agent4SC的框架如图2所示,通过多个模块的协同工作以及策略性使用的表情包,Agent4SC可以生成情感丰富的,多样化的多模态共情回复,克服了LLM和LMM在多模态共情回复生成方面的固有缺陷。

图1 STICKERCONV中的多模态对话的例子, 人工智能助手与用户进行共情对话
Agent4SC的模块介绍:
• 角色模块(Profile Module):我们基于多样化的角色种子数据,使用SELF-INSTRUCT方法构造了2000个独特的用户画像,包含丰富的人物特征和情感标签,使Agent4SC能够模拟多种不同的用户角色。
• 工具模块(Tool Module):在SER30K数据集的基础上,我们使用Llava1.5对sticker数据进行重新标注,并采用CoT方法结合gpt-3.5-turbo整理每个sticker的标注信息,形成包括“description, emotion, recommendation”的三条知识,并以<image, knowledge>对的形式构建了sticker向量数据库。此外,我们定义了agent的关键动作“retrieve”,允许agent通过query主动调用sticker向量数据库中的sticker。
• 计划模块(Plan Module):为了确保Agent4SC模仿人类的思考和行动,我们设计了计划模块,包含三个关键动作:“Intention”(基于用户画像和对话历史评估是否使用sticker)、“Query”(如果决定使用sticker,生成计划使用的sticker描述,然后向sticker向量数据库请求TopN个相似的sticker)、“Select”(基于用户画像与对话历史,从TopN个sticker中选择一个最合适的sticker)。
• 记忆模块(Memory Module):为了确保Agent4SC的对话与行为具有连贯性,我们设计了记忆模块,用于存储和检索对话历史和用户画像。
• 动作模块(Action Module):动作模块是Agent4SC与外界的交流接口,它承接计划模块的输出,基于用户画像和对话历史生成共情回复和sticker。
• 管理智能体(Management Agent):为了确保Agent4SC的性能和质量,我们设计了管理智能体,用于监督和调整Agent4SC的行为。
这些模块的协同工作使得Agent4SC能够模仿人类的观察和思考过程,自然流畅地生成共情回复,并使用sticker,从而无需额外指令就能生成情感丰富的多模态共情对话数据。Agent4SC的设计使我们能够生成STICKERCONV数据集,这是第一个专门为多模态共情对话设计的数据集,为多模态共情对话系统的研究提供了重要的基础。

图2 Agent4SC整体框架
2. PEGS
我们设计了一个多模态共情响应生成框架PEGS (PErceive and Generate Stickers),具有感知和生成表情包的能力。图3说明了我们框架的架构。根据不同的图像生成策略,我们基于该框架推导出了三个模型:PEGS-Ret/Gen/RAG,分别表示通过检索、生成和检索增强生成方法来得到图像回复。从技术上讲,我们利用来自 EVA-CLIP 的 ViT-G/14,BLIP-2 的 QFormer和线性层来编码图像,使用Vicuna-7B作为LLM,Stable Diffusion 作为图像解码器。训练时,我们只训练线性层,LLM块中新加的LoRA层,以及解码图像时的Feature Mapper(使用完整的Encoder-Decoder Transformer架构),其他部分冻结。
对于输入,我们先用ViT编码图像,然后通过Q-Former和线性层对齐图像模态和文本模态的语义空间,并且对齐维度,这样图像编码得到的特征向量对LLM来说是和文本输入的embedding等价的,使得LLM得以处理交错的多模态输入。
对于输出,我们在词表中扩充了特殊token [IMG{r}],用于提醒模型,使用这些token的隐层特征来得到图像。这样把多模态回复的生成统一为对token的生成,使得LLM得以生成交错的多模态输出。在PEGS-Ret中,我们使用32个[IMG{r}],当模型生成[IMG{r}]时,把这些token的隐层特征经过Feature Mapper编码后,在表情包向量数据库中检索出一张图片;在PEGS-Gen中,我们同样使用32个[IMG{r}],同样的把这些token的隐层特征经过Feature Mapper编码,然后使用Stable Diffusion进行解码;在PEGS-RAG中,我们使用64个[IMG{r}],使用前32个token的特征编码检索得到一个图像,使用后32个特征token的特征编码作为Stable Diffusion图像生成的condition,在检索得到的图像上进行去噪扩散,这种基于参考图像的表情包生成方式更有助于保证表情包质量的同时扩展生成表情包的多样性。

图3 PEGS整体框架
3.多模态共情回复评价
LLM 能够像人类一样进行评分,为文本和表情包输出提供分数,从而实现全面的多模态评估系统。我们引入了三个基于 LLM 的指标:(1) 共情:我们通过模型的文本(Empathy-text,EMP-txt)和多模态(Empathy-multimodal,EMP-mm)回复来评估共情。(2)一致性:根据上下文,为文本和表情包回复分配一致性分数,简称CON。(3)排名:我们将不同模型的响应与同一上下文进行比较,根据质量、共情能力和一致性进行评估。
实验结果
表 1 报告了文本指标的结果。PEGS 在 Dist-n 上的性能略低于 Vicuna。这可能归因于 PEGS 扩展了 Vicuna 的词汇量以促进表情包的感知和生成,从而在一定程度上影响了 PEGS 的文本多样性。在我们的实验中,工具学习的训练目标包括文本生成和工具调用。这两个目标可能会相互干扰。因此,工具模型的文本性能达不到文本微调模型的性能。PEGS的端到端结构集成了多模态输入和输出,通过统一的训练目标简化任务,并得到了最佳的文本结果。PEGS-Gen 使用更少的特殊token(32),因此在文本指标上优于 PEGS-Ret 和 PEGS-RAG。这些发现证实了PEGS框架在生成高质量和准确性的文本响应方面的有效性。

表1 PEGS和基线模型 生成文本质量结果
表 2 显示了多模态指标的结果,其中 Freq 表示每个模型的贴纸回复的相对频率。尽管 Vicuna-tool 实现了较高的 MMr (72.48),但这一结果主要是由于其较低的频率 (0.141),这可能不能准确代表其多模态交互能力。PEGS 在 f-MMr 方面表现出色,展示了其集成文本和贴纸的端到端结构,在多模态回复生成方面实现了高度一致性。

表2 多模态指标结果
表3列出了LLM的评估结果。相对于基线模型,两个工具学习模型在排名上优于文本模型。这凸显了表情包在增强共情交流方面的关键作用。根据基于 LLM 的指标结果,PEGS 可以在确保高度一致性的同时生成共情文本,并利用表情包来增强情感共鸣。表 2 和 PEGS-Gen的 EMP-mm (4.353) 表明,多模态回复的质量与其增强共情的程度直接相关。
表4显示了人工评估的结果。除Flu.外,PEGS在大多数评估指标中明显超过两个基线模型,从而证实了PEGS框架的有效性。与ChatGLM3-tool(4.58)相比,PEGS的Flu.(<4.5)较低,可能是因为其高Inf(>4.09)导致Flu.略有减少。根据 Inf 和 Et,信息量是影响共情的关键因素。PEGS-RAG在表情包多样性(3.8)方面表现出色,但在表情包生成质量(3.37)方面得分最低。这一观察结果表明,尽管RAG策略增强了表情包的多样性,但它也可能降低了本实验中表情包生成的质量。对 StiGQ、Es 和 StiD 的分析表明,多模态回复可以增强共情,并且这种增强与回复的质量呈正相关。在考虑对人类指标的所有评估时,PEGS-Gen非常突出,部分原因是它最少地使用特殊token,部分原因是其熟练的表情包生成能力(归功于端到端结构)。这些结果凸显了PEGS-Gen产生高质量、情感共鸣和多样化多模态回复的卓越能力。
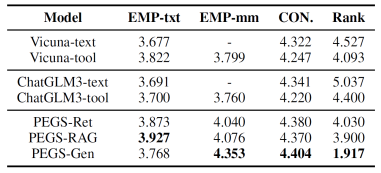
表3 基于LLM的指标的结果

表4 人工评估的结果
总结
我们探索了多模态共情回复的概念,并创建了STICKERCONV,这是第一个专门为多模态共情对话设计的数据集。我们开发了Agent for STICKERCONV,这是一个复杂的基于LLM 的多智能体系统,能够使用表情包模拟类似人类的交互,从而创建多模态共情回复。在STICKERCONV的基础上,我们开发了PErceive and Generate Stickers (PEGS),这是一种先进的多模态共情对话框架。该框架熟练地感知并生成表情包,有效增强了对话体验。此外,我们建立了一套基于LLM的多模态共情任务的综合评估指标。我们相信,这项工作将推进多模态共情对话系统领域研究。
